Redis caching
November 6, 2019•306 words
Redis:
In memory data structure store which is memory backed, provides fast read/write, persistance, replication, automatic failover, replication.
Redis is not a cache as such, as it suppors many different complex data types, but can be configured to be a cache based on some specific options.
AWS supports replication and automatic failover:
#### Replication
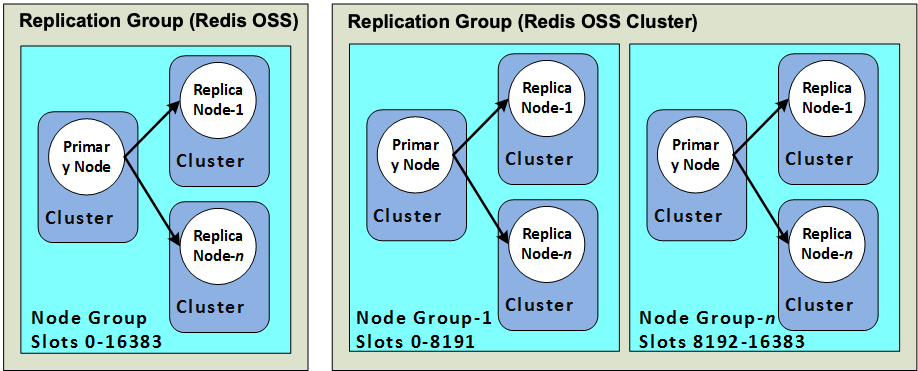
Replication in AWS can be configured in 2 different ways, you can have cluster mode on or cluster mode off. With custer mode off you get one primary replication group, that consists of one primary node and up to 5 replica (read) nodes. The replica nodes are seperate nodes in AWS, which can be spread across subnets to improve redundancy, you can also enable failover in aws, which allows redis to detect problems with the primary node, and begin to promote a read node to be the new primar node, whilst executing the failing node and replacing it with a new read node.
With cluster mode on, you get the same features as the clustermode off configuration, but with multiple primary nodes, this of course aids with redundancy and spreads the load horizontally. However there consitency guarantees between the multiple primary nodes is not strong, meaning you can get cache misses when data has been written to one primary nodes, but that data has not been replicated to other primary nodes yet.
Once a redis instance begins to fill up, in some uses cases you may not care, or simply increase the size or destroy it, however with a cache, this is of course not good as suddenly data being written to the cache fails. Redis facilitates this by offering cleanup methods, which will try use some metric to delete items in the cache that are not being used that often. It supports multiple different methods, which are best described here